

Your friendly neighborhood EM
“Being an engineering manager isn’t just status reports and bureaucracy, it’s a crash course in process design, and AI isn’t the savior many think it is.”
As my overall job description as a Software Engineer becomes increasingly blurry, with recent AI news mostly including bold, yet weird statements in interviews with NVIDIA CEO Jensen Huang and the cries for the bubble being louder than ever, I thought to try something LLMs might actually be good at (reliably), before I start my apprenticeship on learning how to repair the robots.
I've recently dabbled in Engineering Management as I got the chance to manage a team in the interim (due to the temporary absence of a full EM). I thereby got the chance to see the underbelly of what keeps an Engineering Team together. I've long been skeptical about the job of an EM, since I feel that most engineers develop a good feeling for what's important and what's not, hence the EM role seemed almost ceremonial at times.
Companies do need someone to give out the performance reviews and usually also need someone to act as the Team's main point of contact. As an EM, you're responsible for the delivery of a piece of Software, yet to me, this overlaps heavily with the Tech Lead role one sees in many companies.
Easy. I can do that. Being an EM cannot possibly that hard.
I love being wrong. A big, big shout out here to all my EM friends: you're the best, I adore and praise you <3.
For me, sitting in between the positions right now, being a Staff Engineer at Heart, a software engineer by vocation and an Engineering manager by obligation, I am having the time of my life gathering insights on company processes, both via looking from the outside in and looking from the inside out at the same time.
Turns out, as companies grow, their processes grow with them. They also usually grow faster than people can keep track of, leading to quite a few tickboxes to check, checkboxes to tick and so, so many status updates.
The curious case of "workslop"
Being an EM for even a short period of time gave me a front-row seat to how quickly everyday workflows become complicated and how much time gets eaten up by dependencies created by others.
At the same time, we live in an era where producing artifacts has become extraordinarily cheap. With AI tooling, it’s easier than ever to generate documents, reports, updates, and “alignment material”. The result is that critically examining our processes has never been more important and paradoxically, it’s often the first thing to fall by the wayside.
This is where the term “workslop” starts to make sense:
What’s changed isn’t that workslop exists, but it’s that AI makes producing it nearly free.
And in all of this, EM work comes in a lot of different forms:
- change management
- spreadsheets (many, many spreadsheets)
- updates to post
- regular feedback cycles
- interfacing with other teams (e.g. adopting a company-wide process)
- more reports to fill out
- stakeholder management
- keeping track of ownership, alignment, and an ever-evolving process around you
In short: it increases dependencies on you and your team faster than you can possibly fulfill them.
Previously this wouldn't actually be a problem, as you could automate many of these tasks and processes would evolve relatively slowly.
Processes evolve faster and people are now equipped with AI-powered tooling in order to ever increase the things to report and the amount of documents to read and to reflect on. This all comes with a big old multiplier in the form of managing more than one team as a manager. This phenomenon isn't new: generations of Tech Workers have told the tale already and the media made fun of it plenty.
From “bullshit jobs” to workslop
This isn't new, but new at scale.
If David Graeber were still alive, I suspect he’d be warning us about workslop as the natural continuation of the “bullshit jobs” he described years ago.
Technology can now create the illusion of productivity at scale, while quietly eroding the very efficiency it promises. The work looks serious. The artifacts look impressive, but the net effect is often negative.
Anecdotally, I’ve worked in more than one organization where I wasn’t entirely sure whether the people maintaining certain processes were optimizing for efficiency or for the continued existence of the process itself.
And to be fair: those two goals can be in direct conflict, as when a process becomes fully stable, the role maintaining it might no longer be needed.
The uncomfortable tension
As someone who sits firmly on the left side of the political spectrum, this creates a genuine internal conflict for me.
On the one hand, I deeply care about job security and the people behind these roles. On the other hand, companies often interpret “not needed anymore” as a polite “thank you for your service”.
The uncomfortable truth is that processes can be designed in ways that require entire groups of people to create, maintain, and adapt them. Those groups then have a structural incentive to keep the process alive and growing. It's not like the processes themselves are unneeded: lots of them fall into Compliance, Security and Governance, all of which are essential for understanding a company and to grow in accordance with the requirements of modern business.
Thankfully, most people I’ve worked with have had good intentions. We’re all constrained by the systems we operate in. Yet even with the best intentions, those systems can push us toward outcomes that reduce productivity instead of increasing it.
Enter AI, stage left
The power tool isn’t the model. It’s the cost curve.
Today, it’s easier than ever to produce artifacts alongside processes and with AI, it’s easier still to introduce new steps, new requirements, and new forms of reporting.
Change management has always been hard. Now, LLMs are increasingly framed as the solution to organizational rigidity, a way to smooth transitions and accelerate transformation.
Ironically, this often results in more process work, not less.
At that point, it becomes tempting to argue for hiring even more people to maintain the process because surely the existing engineering managers can’t possibly keep up on their own.
The German and French parts of my brain recognize the feeling immediately. Game recognize Game, I suppose.
Bureaucracy, once it takes hold, is very good at defending itself.
So if process work is defining much of Engineering Management’s load, the natural question is: what parts of that load can AI meaningfully take off our plates?
Let's experiment a little!
What are LLMs even good at, reliably?
Before automating anything, it's important to recognize LLMs for what they are and what they are not.
They can be good at some tasks. From personal experience and experimenting, I find these tasks to be (so far):
- Creating greenfield projects where the only customer is me/quality doesn't matter; if there are no stakes and no existing customers, generate away
- Paraphrasing - I often use them to transform my normal written language into English Corporate (something I suck at even after 33 years of speaking English)
- Summaries - to a degree this works for short documents, although I've seen some hilarious examples of this going awry
- Personally, I've seen these added to Gmail and Youtube, where I find them useful to catch me up
The list isn't much longer for me right now. All other tasks, such as brownfield coding (i.e. taking it to an existing code base) usually end in more rework. This is specifically a problem in the OSS space right now, where Maintainers are seeing themselves confronted with tons of unreviewable codeslop.
I suggest supporting maintainers you know and step up for the use and sponsorship of Free Open Source Software, where ever you can.
But even in these examples, gains are marginal without human judgement.
Productivity
There is a marginal increase in productivity here and there for me so far and coding in particular seems only viable with strong compiler guarantees. It ultimately shifts testing back to the right and in the worst case all the way to the customer.
Studies exist for this now - and they don't really show the massive productivity gains promised.
37 months into my job being automated away in 6 months I have to admit for now: The job has changed and tooling has become faster at cranking out code (at a high, but as of now ignorable cost), yet the bottlenecks remain firm and they're usually not about how fast we can produce code.
Armed with this knowledge, I've sat down to actually inspect some of the jobs I have to do while being an interim EM:
- Setting up team processes (in my specific case, more "reviving and ameliorating" them)
- (Helping to) Cut tickets for the Team in order to them to work on initiatives
- Work together with project management on the How of the What of the Why
- This usually comes in the form of working through BRDs with the PM and PRDs with the team
- Create the monthly reports, track the numbers for the team, report on them, use them as inputs for capacity planning once a quarter
So, in essence, the insight here is that we could potentially absolve our selves from some of the more annoying workload with regards to document reading an ticket cutting. Your mileage may vary, but in essence: Looking at a short document like a PRD and slicing smaller individual bits of work should be rather straightforward.
And since I believe that Jira's User Interface is one of the Four Horseman of the Tech Apocalypse, we might have ourselves have a little project at hand. Naturally, the task that I'd be looking to automate would be ticket creation itself, as deriving tickets from PRDs in a structured manner is my least favorite part of the job.
Ollama and running an LLM
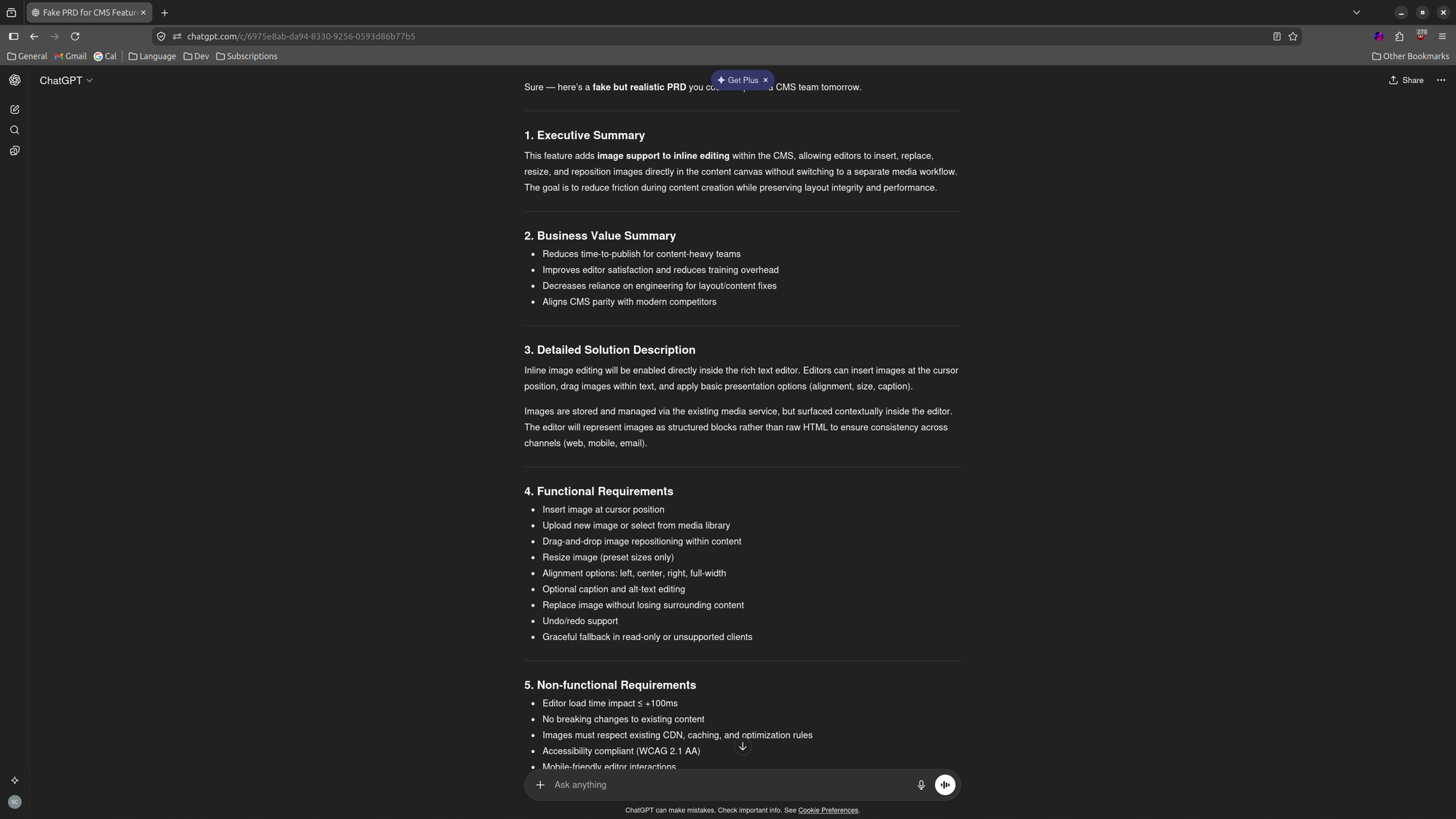
Running Ollama locally eliminates my fear of experimentation, as I don't really want to pump company PRD data into a private cloud LLM (in the absence of having a company provided API Key for OpenAI). Just to be safe, I had ChatGPT generate me a fake PRD for testing purposes, with a basic structure inspired by Claude. We gotta run all the LLMs for this one.
Another aspect of running your LLM locally might be philosophical. It takes away the magic and makes you realize what you're talking to: A model of weights that runs your input to create an output, nothing more, nothing less. There is an almost archaic quality to this. Hearing the fans of the GPU spinning up as the requests run dispels the sorcery of the Black Box that an LLM usually seems like.
I actually have a Gaming Machine standing next to my desk. It sports an NVIDIA Geforce RTX 4080 Super by Inno3D. Nothing too powerful these days and of course, yet far, far away from what a Data center might use.
It turns also out that a GB300 Blackwell doesn't even have a graphics output. 50.000 $USD for a GPU and I cannot even run Stardew Valley in 4k on it? I don't think so, Mr. Jensen! Then again, I don't need an HVAC system, so that's a plus.
All joking aside, let's talk about the setup:
Ollama
Let's install ollama, which is refreshingly straight forward:
# I recommend the manual install, piping from the internet into sh is icky
curl -fsSL https://ollama.com/install.sh | shHow to install ollama
From here on I was surprised to see that ollama sports a docker like workflow and interface. It made me feel right at home yet also caused a thought creeping up the brain stem: "Flo, you did miss out on this, didn't ya?"
# show running models
ollama ps
# show available models
ollama ls
# run a model (opens a prompt interface for the model)
ollama run <model name>
# fetch a model from the interwebz
ollama pull <model name>Different examples of ollama commands
You can browse available models directly on ollama.com. One thing that tripped me up a little was the -cloud suffix, which indicates that Ollama runs the cloud version of the model and immediately prompts credentials.
In the end, I used the OSS version of GPT, i.e. OpenAI's model.
I did try this briefly with the homelab server I built in the last post - after all, it comes with a Radeon chip as well! Suffice it to say: The blog wasn't available while I had to hard restart the machine, sacrificing that sweet sweet uptime.
Running Claude Code
I also did try out running claude
export ANTHROPIC_AUTH_TOKEN=ollama
export ANTHROPIC_BASE_URL=http://localhost:11434
claude --model gpt-oss:20bHow to run claude against a local LLM
It works - if you're happy to wait 4 minutes for generating a simple Rust function. I tried other models here as well, but it turns out that for token intense stuff like coding I have to wait until the data center business crumbles in the fireball of the AI apocalypse before fighting the other raiders for the remaining Blackwell chips (which, let's be real, will probably become a form of commodity money as you cannot even play Brotato on them!).
Vibe coding the tool harness
Freeing ourselves from nightmares of the collapse for the moment, the concept is simple:
- Use the GPU in the machine to run
ollamawith thegpt-oss:20bmodel - Write a small tool that can fetch a PRD document from Confluence (yep, we're using the full Atlassian suite for this one; we could easily swap this out for other tooling later, as many companies also use GDrive or Microsoft products)
- Strip the HTML and convert back to markdown to shrink the context required (I only run a 32.000 token window and I am not made of RAM)
- Inject a bit of additional prompt to generate JSON
- Have the
gpt-oss:20bgenerate an output for us - Inject our own conditions into the structure, such as labels ("ai-generated", these can be useful for later analysis)
- Haul the output as structured requests against the Jira API
The other thing where LLMs can shine is bringing up tooling quickly on a greenfield. My weapons of choice here are always Claude and Rust, as the experience turns out to be great, thanks to the compiler. Extensive user testing stays imperative, otherwise you'd just ship crap quicker.
The model used here is haiku4.5 and the "technique" (if you can call it that) is to use beans, a tool that my colleague Aleks recommended to me. In turn, I recommend you to check it out, since it removes some of the problems with context collapsing by just auto tracking the tasks done while implementing. I am not using it to the full extent here, but being able to store context even in between models with the code is quite handy.
The configuration for Claude is - after installation - just this:
// .claude/settings.json
{
"hooks": {
"SessionStart": [
{ "hooks": [{ "type": "command", "command": "beans prime" }] }
],
"PreCompact": [
{ "hooks": [{ "type": "command", "command": "beans prime" }] }
]
}
}
claude settings for beans
Long story short, turning this:
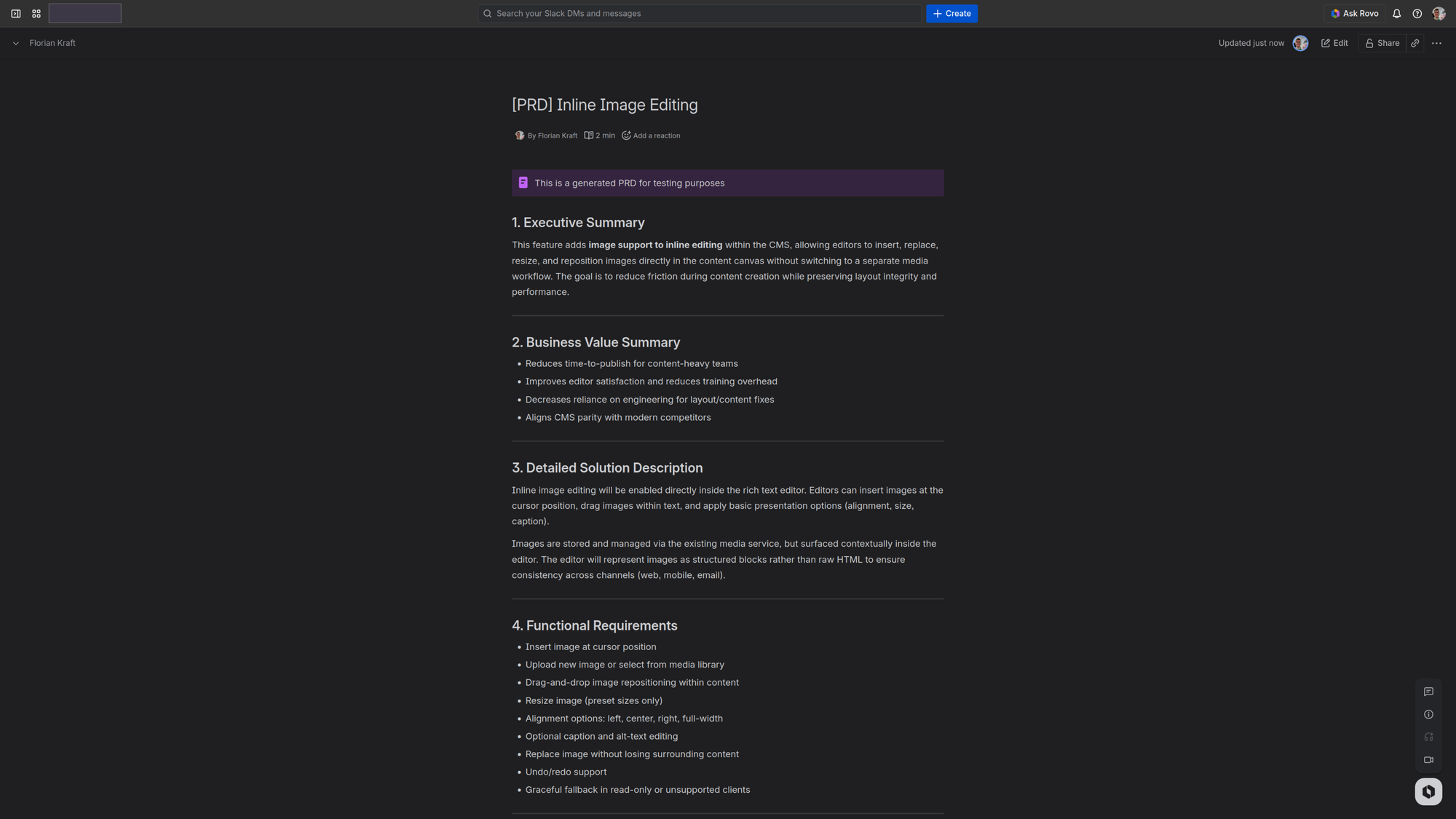
Using this (abbreviated):
$ ./target/release/ticket-slicer run
Fetching PRD from Confluence: <Confluence URL>
Loaded 1 document(s).
Parsing Ollama response as TicketPlan JSON.
Review notes:
## Review of Generated Tickets
### Are any tickets doing more than one thing?
**Yes, several tickets are doing more than one thing:**
1. **"Support image replacement without content loss"** - This ticket combines:
- Implementing image replacement logic
- Preserving surrounding content during replacement
- Both are distinct functional requirements
2. **"Integrate with existing media service"** - This ticket combines:
[...]
Final plan before Jira creation:
{
"project_key": "PROJ",
"epics": [
{
"title": "Inline Image Editing - Core Implementation",
"description": "Implement the core inline image editing functionality within the rich text editor, including insertion, positioning, and basic presentation options.",
"labels": [
"feature",
"editor",
"inline-image"
],
"stories": [
{
"title": "Support image insertion at cursor position",
"description": "Allow users to insert images at the current cursor position in the rich text editor using either upload or media library selection.",
"labels": [
"editor",
"image",
"insert"
],
"subtasks": [
{
"title": "Implement image block insertion logic",
"description": "Create a new block type for images and insert it at the cursor position in the editor.",
"labels": [
"editor",
"block"
]
# [...]
}
Creating tickets in Jira project FLOR at <jira url>
Epics: 3
Created epic FLOR-134
Jira epic link field not set; using parent linkage for story Support image insertion at cursor position.
Created story FLOR-135
Created subtask FLOR-136
# [..]
Jira epic link field not set; using parent linkage for story Validate image content integrity.
Created story FLOR-164
Created subtask FLOR-165
Created subtask FLOR-166
Jira epic link field not set; using parent linkage for story Support undo/redo for image actions.
Created story FLOR-167
Created subtask FLOR-168
Created subtask FLOR-169
Output for running the ticket slicer program on my local machine, turning the PRD into Epics, Stories and Subtasks in Jira
ultimately into this:
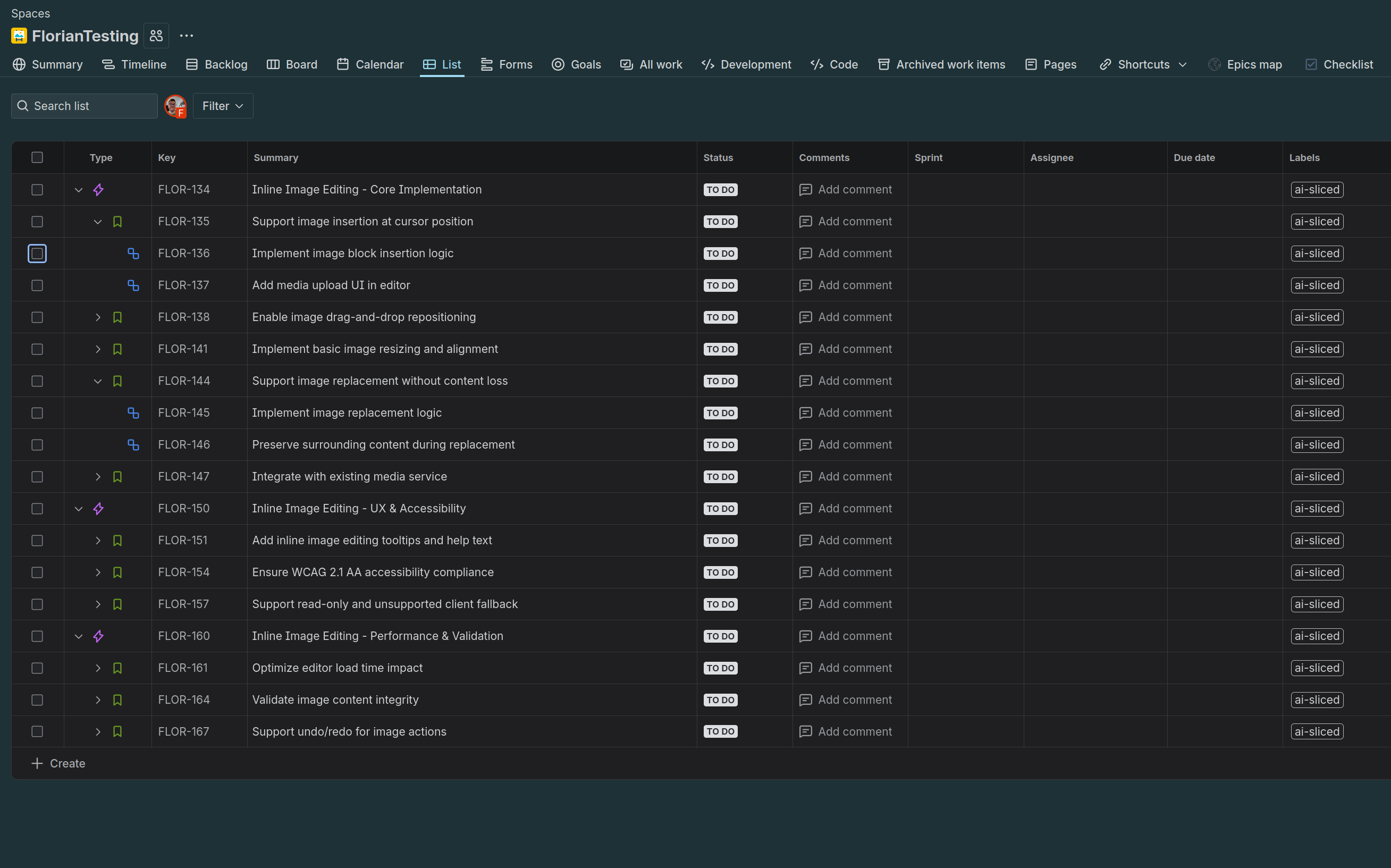
in under 3 minutes was quite satisfying. For clarification: I actually ran a second prompt with the output of the first one, a process commonly labelled "thinking" when using Claude or ChatGPT.
This shows promise, but remember: autocomplete is not insight.
The biggest curve ball here on the technical side were request time outs: I could only make this work through streaming responses from the model. At the same time, passing { keep_alive: "5s" } was even more important, since ollama just continues to keep your VRAM after just one prompt by default (leading to me frantically wondering why Wayland didn't want to resize windows properly anymore).
Trying out other models, such as llama3.1 or the qwen3-coder series didn't yield any more significant results. Interestingly enough, I even received well cut tickets from a small gemma3:270m model, which snugly fits into 300MB of VRAM, yet takes a 32k context window. The difference in quality is of course rather large - the smaller model produces much less refined tickets when compared to a larger version of itself (e.g. gemma3:12b).
Thanks to vibe coding, I made the tool take configuration, in order to quickly exchange the moving parts.
# config.toml
[atlassian]
base_url = "https://your-company.atlassian.net"
jira_project_key = "FLOR"
email = "<atlassian email>"
api_token = "<your atlassian token>"
[jira_fields]
epic_issue_type = "Epic"
story_issue_type = "Story"
subtask_issue_type = "Subtask"
[ollama]
base_url = "http://localhost:11434"
model = "gpt-oss:20b"
# this one's important if you don't want the model to linger and
# eat performance that you need for watching that youtube video ;)
keep_alive = "2s"
[openai]
# I prepared the code to actually use OpenAI at some point, since my
# GPU isn't viable at scale
api_key = ""
model = "gpt-4o-mini"
[github]
# feeding in additional context from code repositories to slice tickets
# better and have more engineering context
repositories = []
[labels]
epics = ["ai-sliced"]
stories = ["ai-sliced"]
[inputs]
prd_url = "<the Confluence URL of the PRD>"
[prompts]
# Modifications for the initial prompt
role = "Product Engineer"
additional_context = "Keep stories small and isolated, they all should be
giving customer value independently"
[logging]
verbose = true
At the risk of stating the obvious: This of course isn't the point where I'd say "Mission accomplished". Even though this feels like work, we've created a light form of workslop, since the team now has to check, refine and groom these tickets. The work for the engineers doesn't disappear, we've only made the initial strokes easier. Quality isn't guaranteed with this and the LLM won't take away the discussion with the local experts if these tasks are viable and if the scoping makes sense in the context of the existing work context.
However, we've overcome the White Canvas problem and unblocked a couple of engineers from coming up with an initial plan and a base for discussion. This is itself is worth something, it just doesn't get us to working software just yet. It's tempting to just run the PRD into claude and tell it to just do create working software, but that attempt will be doomed, as we don't have enough context in the world to describe the existing stack and conditions fully.
Personally, I see this as a countermeasure to process overhead. The documents created in the BRD/PRD process are views on a subject matter, understandable by local product experts, as are the tickets to local engineers. To me, this means we've successfully counterbalanced a bit of process with automating the grueling initial part of it, yet we've not successfully understood the problem. It's essentially a form of self defense for your decision making, automating away the first steps, similar to how writing the tool harness via claude doesn't absolve me of understanding the problem. I've yet to find a way to truly reduce the amount of decisions though, as the amount stays the same.
As understanding a problem is at the heart of Software Delivery, we have to accept that we can now generate the artifacts, yet cannot magically gain comprehension of the customer problem or test the software in question. After all, collaboration between humans to produce the best outcome for a customer isn't replaced by the machine. It probably never will be.
In the end AI doesn’t replace human understanding, but it can reduce some of the grunt work. That’s a meaningful step toward higher-value engineering conversations, but not the Holy Grail of productivity multipliers in Software Engineering.
If anything, experimenting with these processes and workflows has given me newfound appreciation of my full-time EM colleagues. You're all doing solid work and I am but an amateur trying to carry the burden for a bit. You're better people than I am whose social batteries are quite limited and I thank you for standing up everyday for better teams, better outcomes and more productivity overall.
P.S. if you're interested in the tool, I can see if I make it OSS in the next update. You can of course write to me for details.
Update: I've received a couple of requests for the tool - you can find it here: https://codeberg.org/floriank/ticket-slicer/.